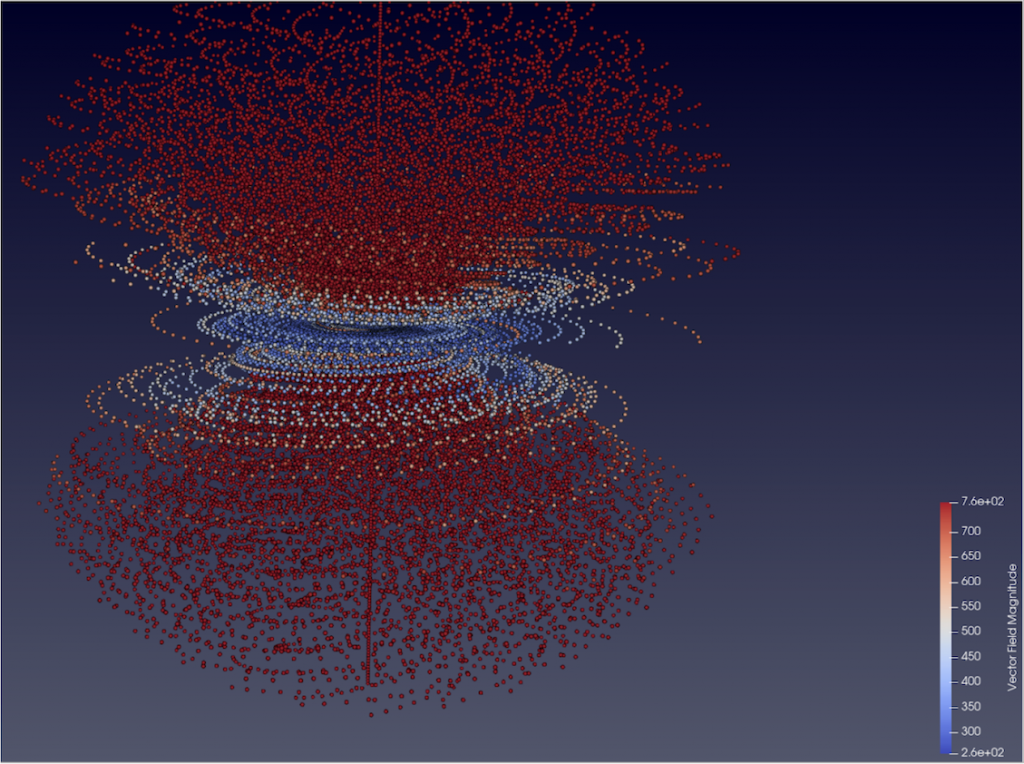
A significant amount of work was done over the past two years to redesign and rebuild the Energetic Particle Radiation Environment Module (EPREM) global numerical model for energetic particle acceleration and transport in the heliosphere, which the PI Kozarev has helped develop and used extensively in the past. Figure 1 shows the non-standard Lagrangian grid that describes the interplanetary flow field, with computational nodes being advected outward by the underlying solar wind. Below, we outline the motivations and results from this development. This large effort will bring great paybacks in our current and future scientific research and space weather forecasting efforts by significantly reducing computational time of runs, improving the model flexibility and extensibility.
Improvements related to “Performance”:
- Tracy integration. Tracy is an instrumentation-based software profiler that has low performance overhead, high precision and resolution, and can capture custom metrics.
- Work scheduling and synchronization. EPREM was designed primarily as an MPI application, relying exclusively on process-based parallelism, meaning each worker in a particular fork/join cycle was an individual process running a single thread of execution. We conducted an investigation of the EPREM’s performance with respect to scheduling and found out that with the current approach EPREM spends 80%-90% of its execution time in cross-process synchronization. In an MPI implementation these fork-joins have to be accompanied by corresponding scatter/gather calls, and in OG EPREM the cost of these 2 scatter/gather calls significantly exceeds the time it takes to compute all 5 operators to integrate the EP distribution forward in time. In our implementation we decided to avoid process based parallelism at first, and instead rely on shared memory of a single process along with a thread pool of workers that accomodate parallelism. In-process memory avoids the need to perform expensive message passing of large amounts of data, and the programming model simplifies to a multithreaded fork-join code. This approach, while taking advantage of the address space sharing, is also limited to executing on a single node because of that. For scaling beyond the limits of a single node, we plan to revise our usage of MPI.
- SIMD implementation alternatives. Today, single instruction, multiple data (SIMD) is widely available on most consumer hardware from desktop to supercomputer scale. At the same, compilers are getting much better at auto-vectorization. In light of that, for each integration operator we have provided alternative implementations that manually implement certain operations with SIMD. In these implementations, we take special care of the memory layout to maximize load/store efficiency. As a result, the runtimes are reduced to almost half in duration relative to a baseline run. This approach has its tradeoffs, and the main one is readablity of the code. In general, even without intrinsics, manual load/store operations, and special control over memory layout make the code more verbose and harder to understand. This is the primary reason these implementations are provided as “alternatives” and not as a direct replacement of the core operators.
Improvements related to “Features”:
- Node distribution on the inner boundary. In order to support the Lagrangian grid formulation, the spatial grid nodes need to be “spawned” and then advected with the solar wind flow. In EPREM, the originating location of these nodes is referred to as the inner boundary, and each individual node is spawned from template positions located on the spherical shell of the inner boundary. Template positions themselves are initialized from a node distribution on a unit sphere, rescaled by the inner boundary radius. To distribute the node positions on the unit sphere, original EPREM tiles each face of the unit cube into a rectangular grid based on the number of rows and columns for each face, then takes the norm of a radius vector pointing to the center of each tile. Unfortunately, this transformation produces highly uneven node placement, with significant clumping towards the edges of the cube. The consequence of such placement bias, is that the spatial distribution of nodes does not uniformly represent the flow differences, and additionally introduces resampling artifacts. We have developed alternative node placement strategies to alleviate this problem.
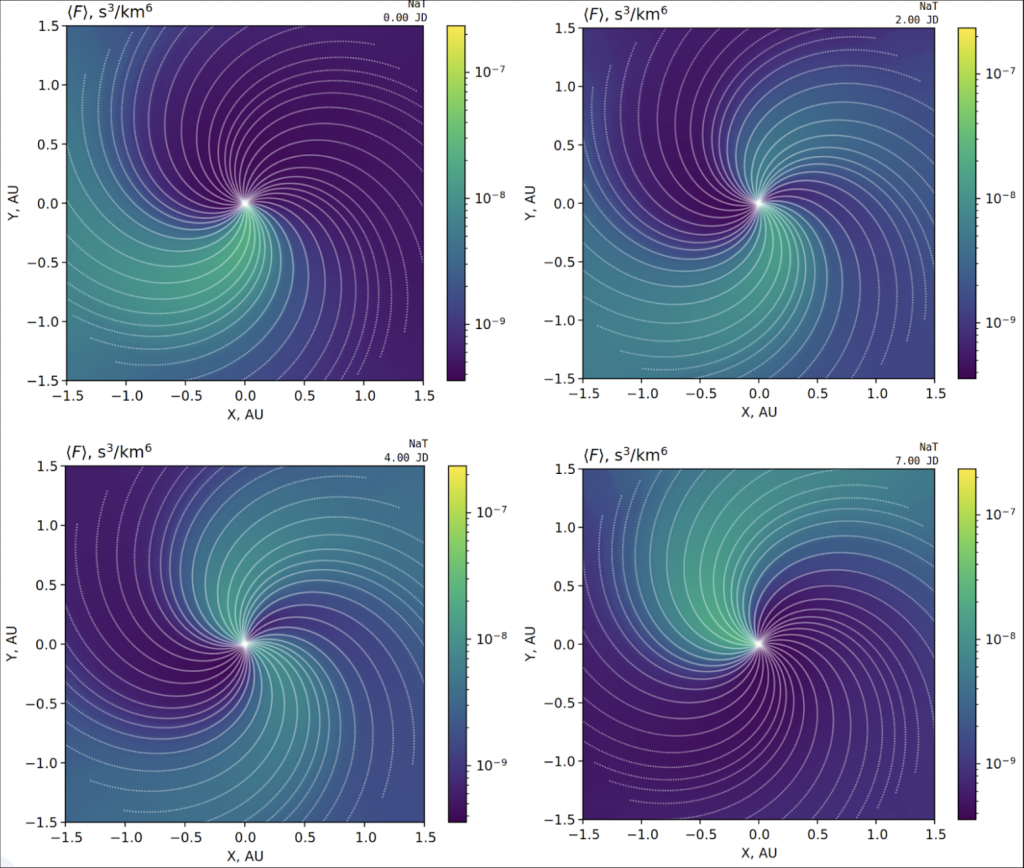
- Seed function series and seed layers. The spatial inner boundary condition is sourced from the injected distribution at the inner boundary of the simulation grid. The model of the distribution at the inner boundary is commonly referred to as the “seed source”. The original EPREM used a the same time-invariable model for the seed source on the entire inner boundary. This is a simplified physical model of a power-law spectrum, but it is sufficient to approximate the real-world spectra in many conditions. In our implementation, the seed model is isolated from the rest of the code, and the exact implementation is made opaque to the caller. The seed interface accepts a list of nodes, energies and pitch angles to apply the seed to, and writes the corresponding values into the destination buffer. The interface remains flexible to satisfy arbitrary seed models, including time- and space-dependent. Figure 2 shows the resulting heliospheric distribution in an equatorial plane, top-down projection.